Zhouhan Lin (林洲汉)
[github name][the simbol][university abbreviation].edu.cn
Office : Room 815B, Neo Bay #1 Building South Tower, No. 951 Jianchuan Road.







Bio
I am an associate professor at the School of Artificial Intellengence and the John Hopcroft Center of Computer Science at Shanghai Jiao Tong University (SJTU). I am leading the Language Understanding and Machine Intelligence Algorithms (LUMIA) Lab. Before joining SJTU, I was a visiting scientist at Facebook AI Research (FAIR) in Menlo Park, CA, working with Michael Auli. I received my Ph.D. in Computer Science from the Mila lab in the University of Montreal in 2019, where I was fortunately supervised by Yoshua Bengio. During my Ph.D., I've been interning at Google AI Language team in the New York City, and at IBM Watson with Bowen Zhou and Mo Yu in Yorktown Height, NY. I also worked as a part-time student researcher at Microsoft Research with Alessandro Sordoni and Adam Trischler in Montreal. Prior to Mila, I received my B.Sc. (2012) and M.Sc. (2014) degrees from Harbin Institute of Technology. For more information, you can find my CV here.
I am actively looking for highly motivated undergrads, interns, and prospective Master's (2027) or Ph.D. (2027) students to work with me. If you are interested in my research topics, please kindly drop me an email, preferably the @sjtu.edu.cn address. Unfortunately, I have no more Ph.D. nor Master positions available for the year 2026.
Research
My core research interest is to explore and develop machine intelligence capable of acquiring, forming, reasoning, and interacting with abstract concepts from large amounts of data, especially through self-supervised learning. Almost all of my research efforts are centered around this goal, touching on a diverse range of topics such as attention mechanisms, language modeling, dialog systems, automated summarization, grammar induction, graph neural networks, code generation, etc. A list of topics that I am interested in at the moment are:
- New neural network architectures beyond decoder-only Transformers, such as learning multi-scale representations, external memory, etc.
- New pretraining tasks beyond next-token-prediction, such as retriever immitation, next-context-prediction, etc.
- Long sequence modeling and efficient models, such as efficient attention mechanisms, KV compression, etc.
Teaching
- CS-1605 Programming Practice (C++) (C++程序设计实践)
- CS-3602 Natural Language Processing (自然语言处理)
News
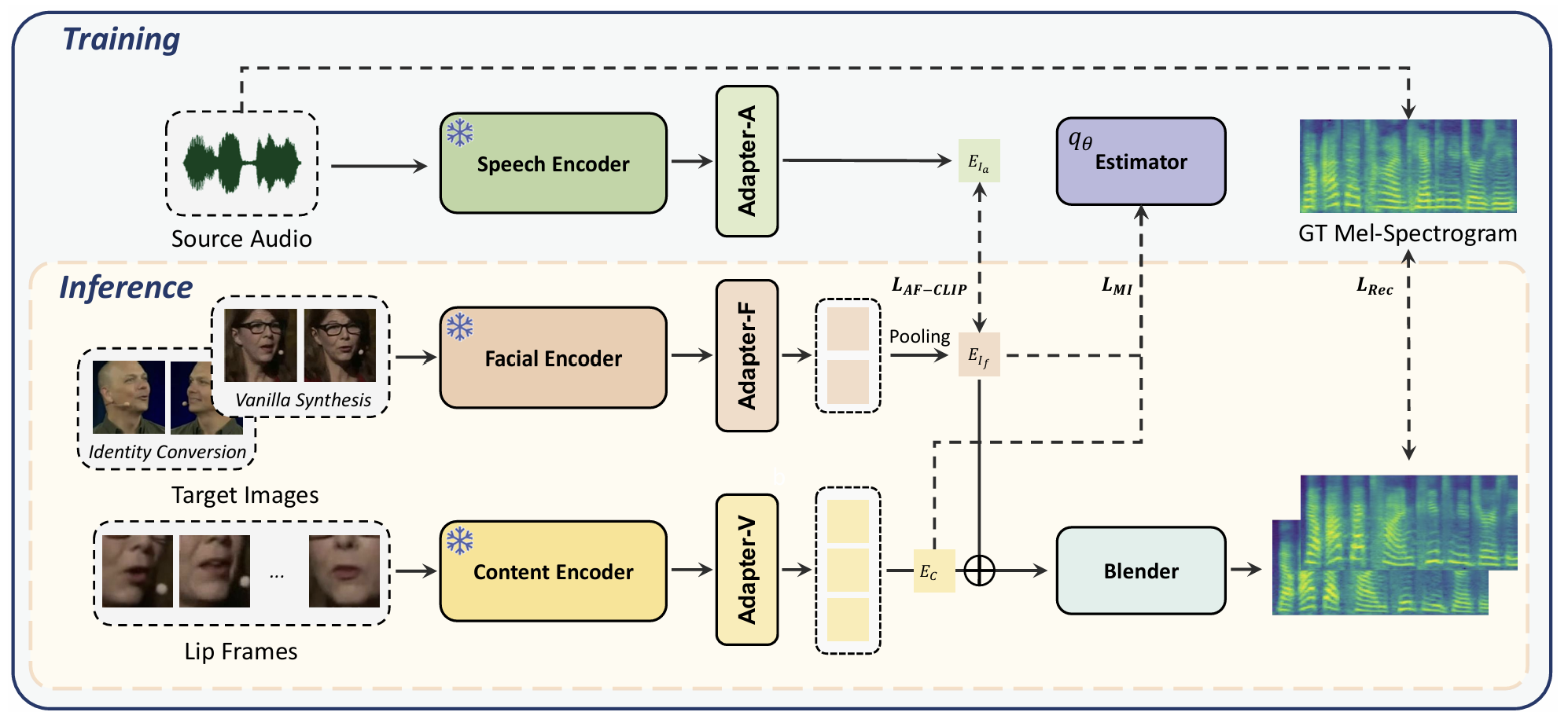
- Dec 2025: Our LUMIA lab members are going to present our Memory Decoder (https://arxiv.org/abs/2508.09874) in NeurIPS! An external memory to LLM that allows you to plug-and-play domain knowledge!
- Nov. 2025: I am serving as the organization chair of MLNLP 2025.
- Nov. 2025: I gave a talk at NYU Shanghai: "New Architectures for LLMs: Preliminary Explorations and Insights" (in English).
- Nov. 2025: I am organizing the workshop on "Efficient LLM architectures" in LMG 2025.
- Aug. 2025: I am serving as the workshop chair for CCL 2025.
- Aug. 2025: I gave an invited keynote talk on CSML 2025, "New Architectures for LLMs: Preliminary Explorations and Insights" (in Chinese).
- Dec. 2024: I gave two talks on CIPS-LMG 2024. The slides can be found here (our NeurIPS work on human-readable fingerprint) and here (the efficient LLM tutorial).
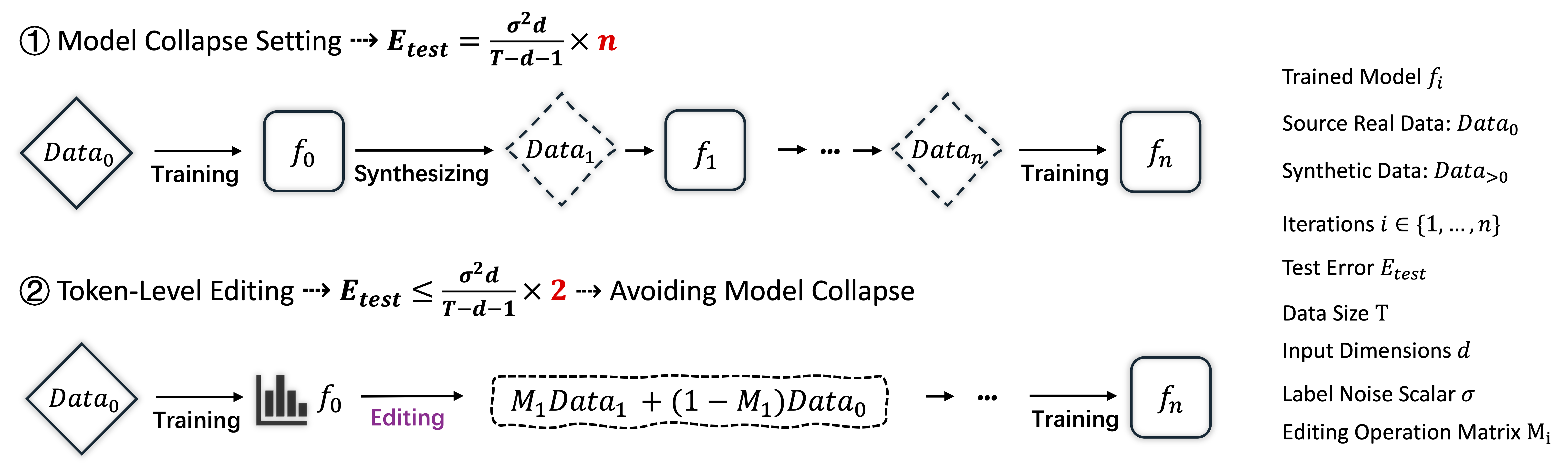
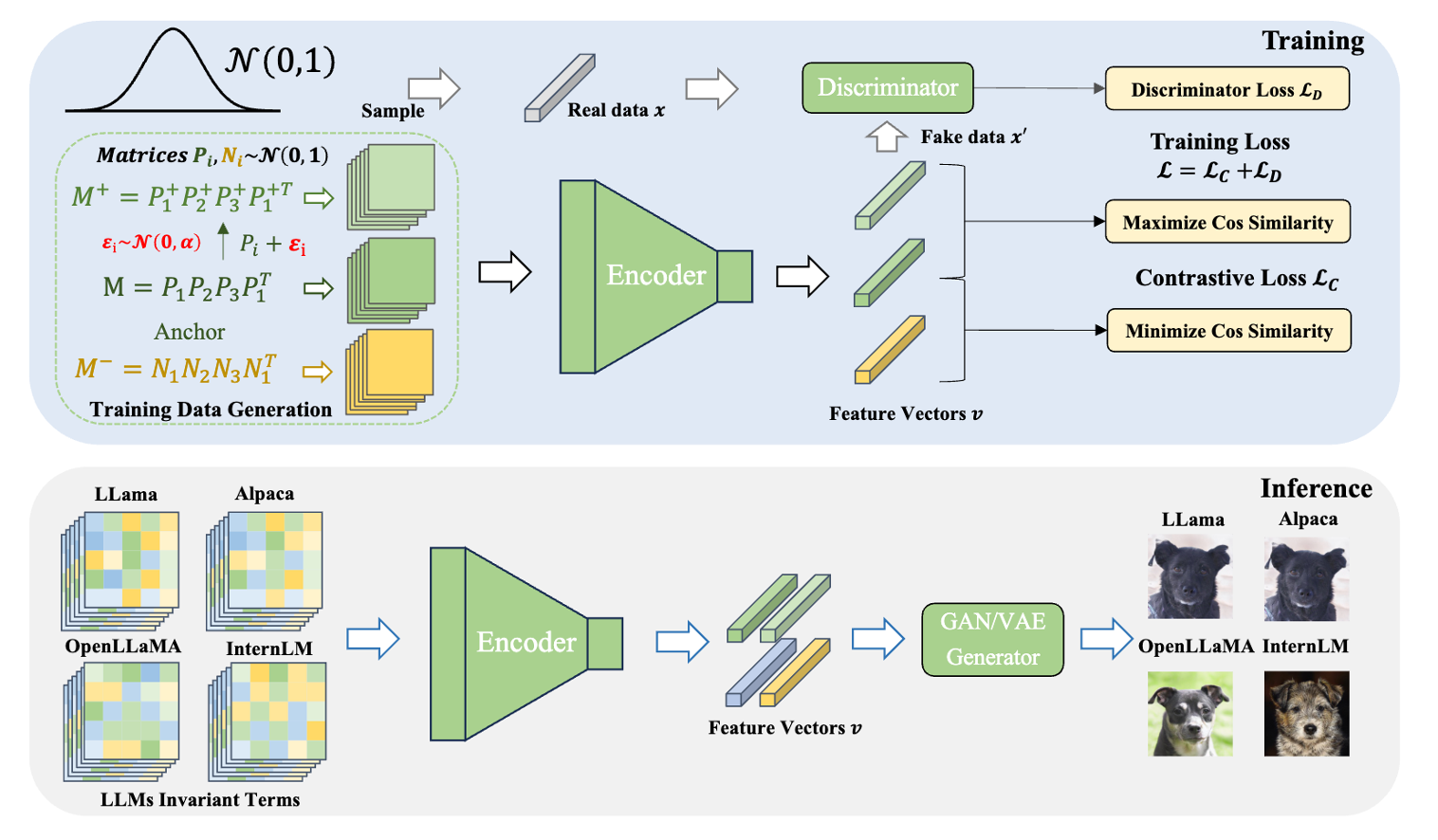
- Sep. 2024: Our human-readable LLM fingerprint ([1]) and Cluster-wise Graph Transformer [2]) got accepted at NeurIPS 2024, with [2] being spotlight!
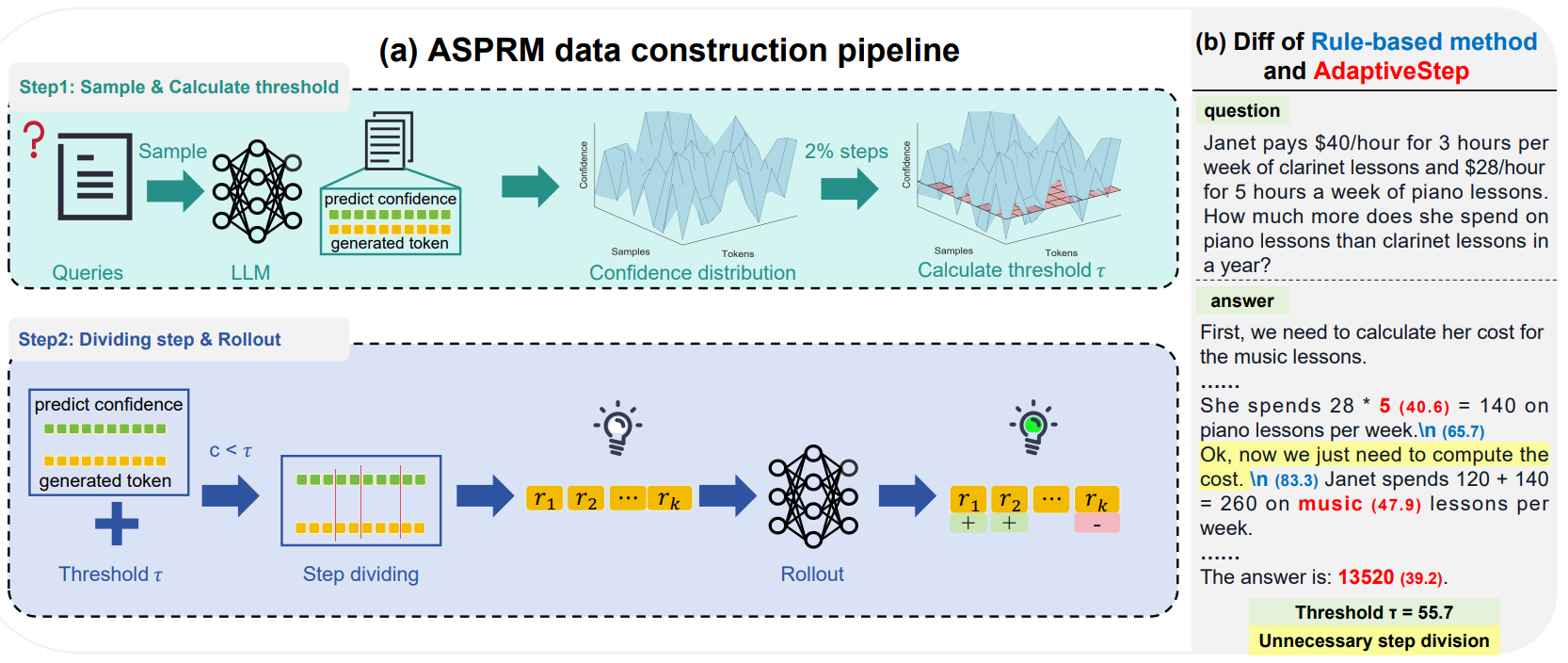
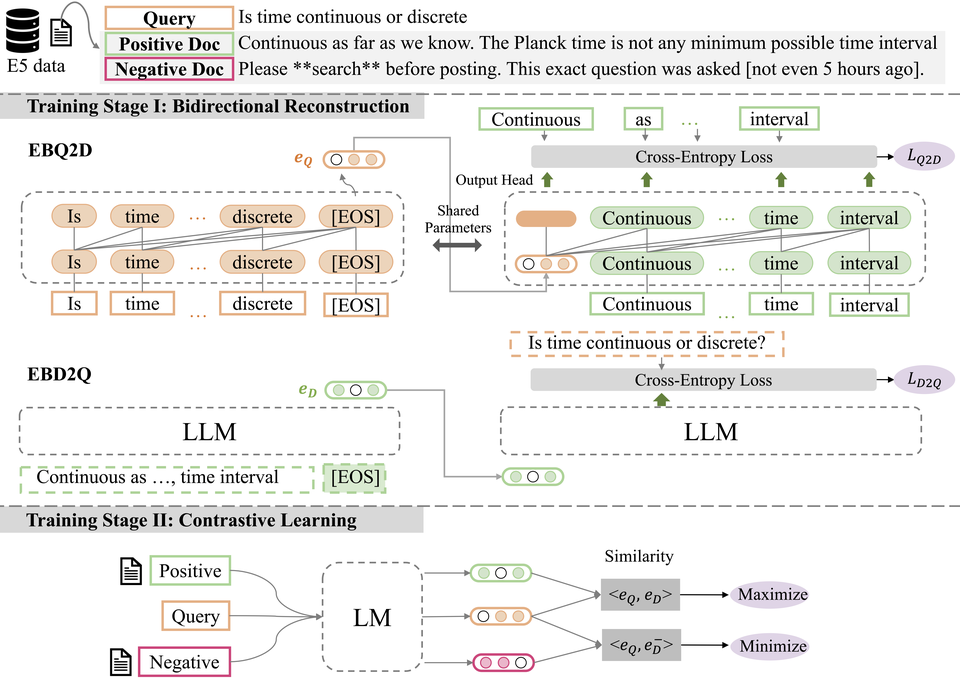
- Sep. 2024: Four papers ([1][2][3][4]) are accepted at EMNLP 2024!
- Jan. 2024: One paper got accepted at ICLR 2024!
- Jan. 2024: Our pretrained geoscience LLMs are fully released! Papers, codes and checkpoints are available! The 30B model, named GeoGalactica (code&checkpoints), is based on Galactica, and the 7B model, named K2 (code&checkpoints), is based on LLaMA.
Selected Publications
This is a selected list of my publications.
For an up-to-date, complete list, please refer to my Google Scholar page.
(*) indicates equal contribution. (#) indicates the corresponding author.
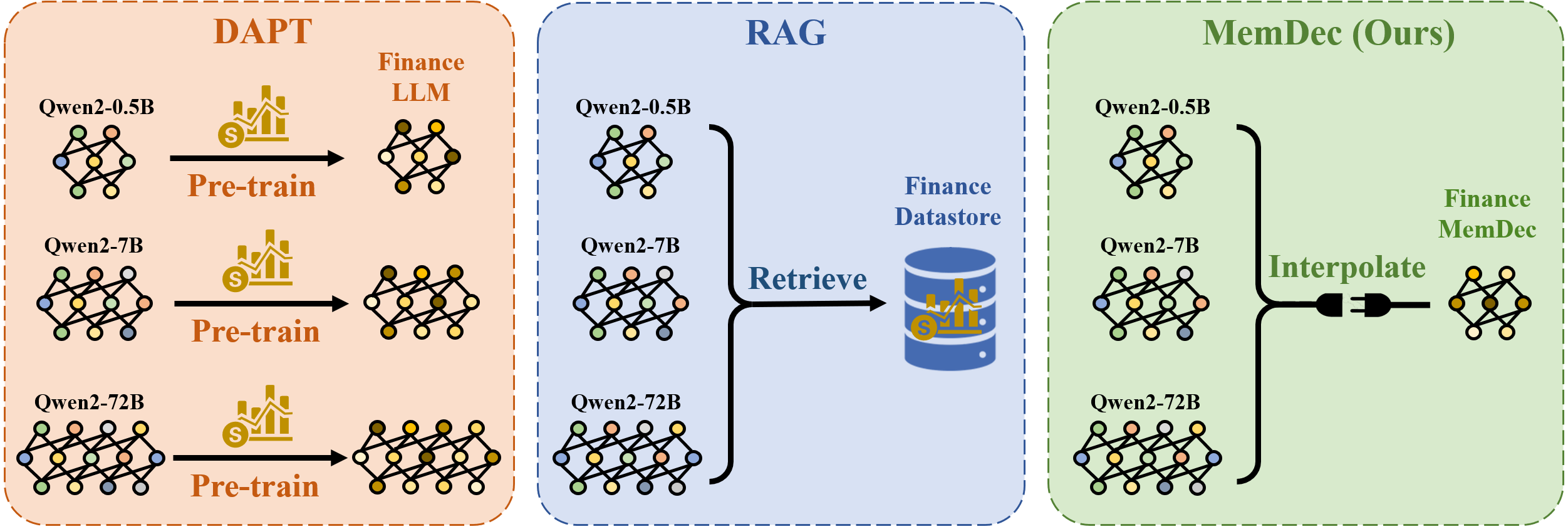
Memory Decoder: A Pretrained, Plug-and-Play Memory for Large Language Models